
はじめに
こんにちは!なたでです!
今回は文字コードの話、特に日本語についての話です。皆さん、第1水準、第2水準、拡張文字、Windows-31J(CP932)に入る文字は一体何かとか、自信を持って把握していますでしょうか。今回は、その辺のワードを一度整理して、まとめてみました。
基本用語
文字コード
文字コードには2つの意味がある。文字集合と符号化方式である。
文字集合
JIS X 0208など、文字の集合である。これをどのように記録するかは符号化方式による。
符号化方式
上記で規定した文字集合を符号化する方式の種類である。ISO-2022-JP、EUC-JP、Shift_JISなどがある。
コードセット
文字集合と符号化方式をまとめたもの。
常用漢字
学校で習う基本的な漢字。1923年に文字集合が生まれ、1981年の時点での常用漢字は1945文字である。
後程説明するが、この漢字が1978年に制定されたJISX 0208のJIS第1水準漢字に含まれる。
改定常用漢字
2010年に常用漢字に対して改定を行った。2136文字(既存の5文字を削除、196文字を追加)となる。例えば、嵐、俺、丼、虹、枕、串、脇といった今では目にする漢字が含まれる。
元の漢字の文字の形にも変更が入り、「剥」という自体が、旧字扱いだった「剝」へ変更があった。この「剝」は元々2000年に制定されたJISX 0213のJIS第3水準漢字の漢字として登録されていたため、後程説明するWindows-31Jは(改定)常用漢字を正しく表示できない。
常用漢字は元々、JIS第1水準漢字だったが、改定常用漢字の「曖」はJIS第2水準漢字、「剝」はJIS第3水準漢字のため、「常用漢字に対応」と謳う場合は注意が必要である。
JIS漢字水準
JISで定められた漢字規格でいくつかの水準がある。
フォント
パソコンの画面上に文字集合を表示させるためのデータ。コードセットが対応していも、フォントが用意されていなければ表示はできない。
JIS漢字水準の種類
JIS第1水準漢字
1981年の常用漢字1945種類を含んだ2965種類ある漢字集。1978年に制定したJISX 0208文字集合に含まれる。常用漢字などの使用頻度が高い文字が含まれる。
2010年の改定常用漢字で、JIS第1水準漢字外の漢字「曖」「剝」が追加されたので注意が必要である。
JIS第2水準漢字
3390種類ある漢字集。1978年に制定したJISX 0208文字集合に含まれる。異体字、旧字体など使用頻度が低い漢字が含まれる。
2010年の改定常用漢字の文字「曖」が含まれる。
JIS第3水準漢字
1259種類ある漢字集。2000年に制定したJIS X 0213文字集合に含まれる。例えば、人名用漢字許容字体や地名で使用される漢字が追加されている。
常用漢字の「剥」の旧字の「剝」が第3水準に登録されている。漢字水準で説明したように、2010年の改定常用漢字で、文字の形がこの第3水準の「剝」に変更されたため、JIS第3水準漢字は一部に常用漢字が含まれた状態になっている。
「𡈽」という漢字が第3水準に登録されている。この記事では詳しく説明しないが、この漢字は、Unicodeに後で登録されたため、CJK統合漢字拡張Bという区域に登録された。このCJK統合漢字拡張Bは、1文字を2バイトで符号化するUTF-16で符号化した場合にサロゲートペアを使用して、4バイトで符号化する必要があるので、JIS第3水準漢字とUnicodeを組み合わせる場合は注意が必要である。
JIS第4水準漢字
2436種類ある漢字集。2000年に制定したJIS X 0213文字集合に含まれる。第3水準以外で、よく利用される文字が追加されている。
JIS漢字水準以外
漢字水準は、1978年のJISX 0208で第1水準と第2水準、2000年のJIS X 0213で第3水準と第4水準で漢字が符号化のために登録されているが、このJISXとは独立して、符号化された漢字がある。
IBM拡張文字の漢字
後程説明するが、WindowsでJISX 0208をShift_JISで符号化することが普及したが、文字が足りないため、外字領域に独自に登録した文字集合で、普及し一般化したもの。このWindows上の独自文字を含めたShift_JISを、Windows-31Jと呼ぶ。
IBM拡張漢字は、2000年のJIS X 0213で、JIS第3水準漢字として取り込まれる「黑」、JIS第4水準漢字として取り込まれる「匤」などがある。
逆に、「髙」など、JIS第3水、JIS第4水準漢字に取り込まれていない。従って、後程説明するが、JISX 0208とJIS X 0213を符号化するShift_JIS-2004では、「髙」は利用できない。
ここでは詳しく説明しないが、IBM拡張文字の漢字を、UTF-16で符号化した際は、サロゲートペアを使用する文字はない。
文字集合の種類
JIS X 0201
ASCIIコードに、片仮名図形文字集合を加えた文字集合。1969年に制定された。1バイトで表すことができるため、文字幅がASCIIコードと同じ半角になっており、後に半角カタカナになっている。
| 符号 | 説明 |
| 0x00~0x1F | ASCIIコード(制御文字) |
| 0x20 | ASCIIコード(空白) |
| 0x21~0x7E | ASCIIコード(図形文字)
JIS X 0201(ラテン文字用図形文字集合) |
| 0x7F | ASCIIコード(制御文字) |
| 0xA1~0xDF | JIS X 0201(片仮名図形文字集合) |
| 0xE0~0xFE | JIS X 0201(未定義) |
0x21~0x7EのJIS X 0201(ラテン文字用図形文字集合)は、ASCIIコードの図形文字とほぼ同一。ほぼというのは、以下の2文字だけがASCIIコードと異なっている。
- 0x5C バックスラッシュ
\が円記号¥ - 0x7E チルダ
~がオーバーライン‾
JIS X 0208
6879字の文字集合。1978年にJIS C 6226-1978として作成され、その後1983年、1990年および1997年と改定している。漢字は、常用漢字などが含まれる第1水準と、第2水準を定義し、それぞれ第1水準2,965文字、第2水準3,390文字が収納されている。漢字以外の記号も含まれる。
追加された文字は、区と点で定義されている。1区画は94つの文字が定義されており、JIS X 0208では、1区から94区までを定義している。
それぞれの区には次の文字が入る。
| 区 | 収められている文字 |
| 1区~2区 | 特殊文字 |
| 3区 | 数字とラテン文字 |
| 4区 | 平仮名 |
| 5区 | 片仮名 |
| 6区 | ギリシア文字 |
| 7区 | キリル文字 |
| 8区 | 罫線素片 |
| 9区~15区 | 空き領域 |
| 16区~47区 | JIS第1水準漢字 |
| 48区~84区 | JIS第2水準漢字 |
| 85区~94区 | 空き領域 |
空き領域は、文字は規定されておらず、使用してはいけないとされている。
JIS X 0212
6879字の文字集合。1990年に制定。JIS X 0208とは重複しない、特殊文字21字、アルファベット245字、漢字5801字の合計6067字を定義。
JIS X 0208と、組み合わせて使うJIS補助漢字として制定されたが、文字集合を符号化するためのShift_JISと相性が悪く、普及はしていない。この文字集合の符号化方法としては、EUC-JPなどがある。
JIS X 0208と同様に、区と点の概念があり、IMEパットの文字一覧から、以下のように定義されていることが分かる。
| 区 | 収められている文字 |
| 1区 | 空き領域 |
| 2区 | 記号 |
| 3区~5区 | 空き領域 |
| 6区~7区 | アルファベット |
| 8区 | 空き領域 |
| 9区~11区 | アルファベット |
| 12区~15区 | 空き領域 |
| 16区~77区 | JIS補助漢字 |
| 78区~94区 | 空き領域 |
JIS X 0213
2000年に制定されたJIS X 0208:1997を拡張した文字集合。JIS第3水準漢字とJIS第4水準漢字の漢字、及び記号等含めて4354字が追加されており、6879+4354=11233字の文字集合となる。漢字以外の文字も含まれる。NEC特殊文字はそのまま採用された。2004年に改定したJIS X 0213:2004では、もともとあったフォントの字形を変形しており、同一文字でも見た目が変わる場合がある。
JIS X 0212で符号化が出来ていなかった反省を生かし、Shift_JISでの符号化についても定義している。JIS X 0213の拡張をした符号化として、Shift_JIS-2004、EUC-JIS-2004がある。なお、JIS X 0212の文字集合の漢字の一部は、JIS第3水準漢字とJIS第4水準漢字で再定義された上で取り込まれている。
JIS X 0208:1997を拡張する際に、面という概念を追加。1面は、JIS X 0208で利用していなかった部分に記号と、第3水準漢字を追加。2面は第4水準漢字を追加している。2面に関しては、JIS X 0212で定義した区と被らない箇所を利用している。
追加した漢字は、符号化できず普及しなかったJIS X 0212と被っている漢字がある。
| 面 | 区 | 収められている文字 |
| 1面 | 1区~10区 | JIS X 0208の文字+α※
※各区の末尾の未使用箇所に記号/平仮名/片仮名を追加 |
| 1面 | 9区~11区 | アルファベット |
| 1面 | 12区~13区 | 特殊記号(NEC特殊文字含む) |
| 1面 | 14区~15区 | JIS第3水準漢字 |
| 1面 | 16区~17区 | JIS X 0208のJIS第1水準漢字
※17区の未使用部分に第3水準漢字を追加 |
| 1面 | 48区~84区 | JIS X 0208のJIS第2水準漢字
※84区の未使用部分に第3水準漢字を追加 |
| 1面 | 85区~94区 | JIS第3水準漢字 |
| 2面 | 1区 | JIS第4水準漢字 |
| 2面 | 2区 | 未定義(JIS X 0212で使用済みの区のため) |
| 2面 | 3区~5区 | JIS第4水準漢字 |
| 2面 | 6区~7区 | 未定義(JIS X 0212で使用済みの区のため) |
| 2面 | 8区 | JIS第4水準漢字 |
| 2面 | 9区〜11区 | 未定義(JIS X 0212で使用済みの区のため) |
| 2面 | 12区~15区 | JIS第4水準漢字 |
| 2面 | 16区~77区 | 未定義(JIS X 0212で使用済みの区のため) |
| 2面 | 78区~94区 | JIS第4水準漢字 |
Windows-31J文字集合
WindowsのShift_JISの実装で利用できる文字集合。通常のShift_JISに比べて拡張されているため、別の文字集合と考えた方がよい。
- JIS X 0208
- IBM拡張文字
- NEC選定IBM拡張文字
- NEC特殊文字
| 区 | 収められている文字 |
| 1区~12区 | JIS X 0208の文字(英数字記号) |
| 9区~12区 | 空き領域 |
| 13区 | NEC特殊文字 |
| 14区~15区 | 空き領域 |
| 16区~84区 | JIS X 0208の文字(JIS第1、2水準漢字) |
| 85区~88区 | 空き領域 |
| 89区~92区 | NEC選定IBM拡張文字 |
| 93区~94区 | 空き領域 |
| 95区~114区 | JIS C 6226範囲外/未定義 |
| 115区〜119区 | JIS C 6226範囲外/IBM拡張文字 |
NEC特殊文字
JIS X 0208の範囲内の未定義部分(13区)に独自に追加した記号。CP932で言うと0x8740~0x879Cである。後に制定されたJIS X 0213に流用されている。
IBM拡張文字
Windowsが用意した外字領域(JIS C 6226範囲外)を用いて、IBMが定義(115区〜119区)した文字列。CP932で言うと0xfa40~0xfc4bである。
NEC選定IBM拡張文字
IBM拡張漢字をJIS X 0208の空き領域の範囲内(89区〜92区)にNECが移動させた文字列。CP932で言うと0xed40~0xeefcである。つまり、CP932では、同じ文字がIBMの範囲と、NEC選定部分とで2か所含まれる場合がある。
外字
Windowsでは独自に自由に文字を追加できる外字の領域を用意していた。CP932で言うと0xf040~0xf9fcである。JIS X 0208の集合範囲外の範囲であるが、後に制定されたJIS X 0213の範囲内でもある。JIS X 0208の1997年における改訂で、今後の互換性を維持するために、この未定義領域に外字を入れることが禁止された。
Unicode
全世界の文字を入れた文字集合である。
外字領域もマッピングされており、Shift_JISの外字0xf040~0xf9fcは、UnicodeのU+e000~U+e757と対応する。
符号化方式の種類
ISO-2022-JP(JISコード)
7ビットで表す文字符号化。エスケープシーケンスが入る特徴を持つ。メールなどで利用されている。
符号化の計算
JIS X 0208の区をk、点をtとした場合、以下の式から2バイトで符号化する。
$$j_1=k+\mbox{0x20}$$
$$j_2=t+\mbox{0x20}$$
区と点は1~94なので、符号化後は0x21~0x7Eとなり、7ビットで表すことができる。
このままではASCIIコードが利用できないため、実際にはエスケープシーケンスを組み合わせて表現する。例えば、JIS X 0208-1990を使用する場合は、以下のバイト列を加える必要がある。
| 1バイト目 | 2バイト目 | 3バイト目 | 4バイト目 | 5バイト目 | 6バイト目 | |
| 意味 | ESC | & | @ | ESC | $ | B |
| 16進数 | 0x1B | 0x26 | 0x40 | 0x1B | 0x24 | 0x42 |
ASCIIコードに戻す場合は、以下のバイト列を加える。
| 1バイト目 | 2バイト目 | 3バイト目 | |
| 意味 | ESC | ( | B |
| 16進数 | 0x1B | 0x28 | 0x42 |
円マークが利用できるJISのローマ字(JIS X 0201)を使用する場合は、以下のバイト列を加える。
| 1バイト目 | 2バイト目 | 3バイト目 | |
| 意味 | ESC | ( | J |
| 16進数 | 0x1B | 0x28 | 0x4A |
半角カタカナ(JIS X 0201)を使用する場合は、以下のバイト列を加える。
| 1バイト目 | 2バイト目 | 3バイト目 | |
| 意味 | ESC | ( | I |
| 16進数 | 0x1B | 0x28 | 0x49 |
Shift_JIS(SJIS)
ASCIIコードや半角カタカナは1バイト。日本語を含むものは2バイトで表す符号化。1バイト文字は半角文字、2バイト文字は全角文字と呼ばれる。Shift_JISを開発設計者は、JIS X 0201と、JIS X 0208を含めてよいと企図している。
符号化の計算
区をk、点をtとした場合、以下の式から1~2バイトで符号化する。符号化後の1バイト目は区、2バイト目は点を表す。
$$s_1 = \begin{cases} c & \mbox{if JIS X 0201} \\
\left \lfloor \frac{k + 257}{2} \right \rfloor & \mbox{if } 1 \le k \le 62 \\
\left \lfloor \frac{k + 385}{2} \right \rfloor & \mbox{if } 63 \le k \le 94 \\
\end{cases}$$
$$s_2 = \begin{cases} t + 63 + \left \lfloor \frac{t + 32}{96} \right \rfloor & \mbox{if } k \mbox{ is odd }\\
t + 158 & \mbox{if } k \mbox{ is even } \\
\end{cases}$$
区と点の符号化後のマッピングは次のようになる。
区
- 区が62以下なら、129~159(0x81~0x9F)
- 区が63以上なら、224~239(0xE0~0xEF)
※floorの式があるように1つの値あたりに、2区分を記録する。
点
- 区が奇数
- 点が63以下なら、64~126(0x40~0x7E)
- 点が64以上なら、128~158(0x80~0x9E)
- 区が偶数
- 159~252(0x9F~0xFC)
マッピング図
より理解を深めるために、文字集合JIS X 0208の文字の区と点を、Shift_JISにマッピングした場合をHSP言語を用いて可視化してみる。
#module
#defcfunc toSJIS int men, int ku, int ten, local s1, local s2
if(men == 1) {
if(ku <= 62) {
s1 = (ku + 257) / 2
}
else {
s1 = (ku + 385) / 2
}
}
else {
if(ku <= 15) {
s1 = (ku + 479) / 2 - (ku / 8) * 3
}
else {
s1 = (ku + 411) / 2
}
}
if(ku & 2) {
s2 = ten + 63 + (ten + 32) / 96
}
else {
s2 = ten + 158
}
return s2 << 16 | s1
#global
この関数を利用して、以下を実行して図を作成する。
screen 0, 256, 256
color 128, 128, 255
boxf
men = 1
repeat 94, 1
ku = cnt
if(men == 1) {
if(((9 <= ku) && (ku <= 15)) || ((85 <= ku) && (ku <= 94))) {
v = 32
}
else {
v = 128
}
}
repeat 94, 1
ten = cnt
code = toSJIS(men, ku, ten)
hsvcolor ku, 255, v + ten
pset code >> 16, code & 0xff
loop
loop
可視化した図は以下の通りである。横が1バイト目、縦が2バイト目の値とし、256×256のキャンバスにマッピングを行った。
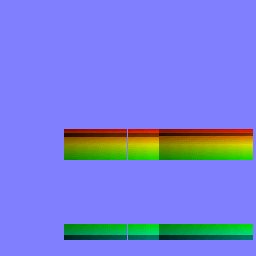
縦に線が入っているのは、1バイト目が0x7Fとなりえないためである。また暗い部分は空き領域を示している。
Windows-31J(CP932、Microsoftコードページ932)
Windowsでは、上記のShift_JISの範囲に加えて、IBM拡張文字の範囲、NEC特殊文字の範囲、NEC選定IBM拡張文字の範囲、外字の4種類を含む形でShift_JISで記録しており、これがWindows-31Jである。仕様を決める際に例えば、Shift_JISの文字の範囲と言ったときに、本来のShift_JISの範囲なのか、あるいは独自拡張したWindows-31Jの範囲なのか、使用者には用語の確認が求められる。なおWindowsが当初Shift_JISの範囲にメーカー独自で変更を加えてもいいというCP932が作成され、これに対して拡張を加えたものをWindows-31Jとして登録した経緯となるが、拡張文字を含めた文字含めてCP932と呼ぶ場合もある。
符号化の計算
Shift_JISとほぼ同一の符号化で可能である。違う点は、区が94までという制限を解除している点だけである。
マッピング図
理解を深めるために文字集合JIS X 0208のときと同様に、文字集合Windows-31JのShift_JIS符号化マッピングを行った。
区は94を超えて119区まで計算を行っている。また、94区から114区の当てはめは行わなかった。
screen 1, 256, 256
color 128, 128, 255
boxf
men = 1
repeat 119, 1
ku = cnt
if(men == 1) {
if(((9 <= ku) && (ku <= 12)) || ((14 <= ku) && (ku <= 15)) || ((85 <= ku) && (ku <= 88)) || ((93 <= ku) && (ku <= 114))) {
v = 32
}
else {
v = 128
}
if((95 <= ku) && (ku <= 114)) {
continue
}
else: if(115 <= ku) {
_h = 32
}
}
repeat 94, 1
ten = cnt
code = toSJIS(men, ku, ten)
hsvcolor ku + (men - 1) * 96 + _h, 255, v + ten
pset code >> 16, code & 0xff
loop
loop
以下が、Windows-31Jである。NEC特殊文字とNEC選定IBM拡張文字が入ることで、空き領域が一部減っていることが分かる。下の部分で増えた紫の部分はIBM拡張文字である。

以下の文字集合JIS X 0208のShift_JIS符号化と比較するとよい。
Shift_JIS-2004
JIS X 0213のJIS第3水準漢字とJIS第4水準漢字と追加アルファベット/記号を加えたShift_JIS。
NEC選定IBM拡張文字(0xed40~0xeefc)はJIS第3水準漢字に、IBM拡張文字(0xfa40~0xfc4b)はJIS第4水準漢字に、それぞれバッティングしている。NEC特殊文字(0x8740~0x879c)はそのまま取り込まれている。
符号化の計算
面をm、区をk、点をtとした場合、以下の式から1~2バイトで符号化する。
$$s_1 = \begin{cases} c & \mbox{if JIS X 0201} \\
\left \lfloor \frac{k + 257}{2} \right \rfloor & \mbox{if } m = 1 \mbox{ and } 1 \le k \le 62 \\
\left \lfloor \frac{k + 385}{2} \right \rfloor & \mbox{if } m = 1 \mbox{ and } 63 \le k \le 94 \\
\left \lfloor \frac{k + 479}{2} \right \rfloor – \left \lfloor \frac{k}{8} \right \rfloor \times 3 & \mbox{if } m = 2 \mbox{ and } 1 \le k \le 15 \\
\left \lfloor \frac{k + 411}{2} \right \rfloor & \mbox{if } m = 2 \mbox{ and } 78 \le k \le 94 \end{cases}$$
$$s_2 = \begin{cases} t + 63 + \left \lfloor \frac{t + 32}{96} \right \rfloor & \mbox{if } k \mbox{ is odd }\\
t + 158 & \mbox{if } k \mbox{ is even } \\
\end{cases}$$
m=2の場合のkは、実際には飛び飛びになっているため、もし、より正確に書くのであれば計算式のIF文でkの値を細かく区切るべきかもしれない。
マッピング図
文字集合JIS X 0208+JIS X 0213のShift_JIS-2004符号化マッピングを行う。
screen 2, 256, 256
color 128, 128, 255
boxf
v = 128
repeat 2, 1
men = cnt
repeat 94, 1
ku = cnt
if(men == 2) {
if((ku == 2) || ((6 <= ku) && (ku <= 7)) || ((9 <= ku) && (ku <= 11)) || ((16 <= ku) && (ku <= 77))) {
continue
}
}
repeat 94, 1
ten = cnt
code = toSJIS(men, ku, ten)
hsvcolor ku + (men - 1) * 96, 255, v + ten
pset code >> 16, code & 0xff
loop
loop
loop
以下は、マッピング結果である。赤くなっている部分は、2面の第4漢字水準である。文字集合JIS X 0208のShift_JIS符号化に比べて、第3水準の漢字が追加されたため空き領域が全てなくなっていることも確認できる。

以下の文字集合JIS X 0208のShift_JIS符号化と比較するとよい。
EUC-JP
UNIXなどで利用されていた文字符号化。Windows-31JのEUC-JP対応版にeucJP-msがある。またShift_JIS-2004のEUC-JP対応版にEUC-JIS-2004がある。
符号化の計算
以下は、JIS X 0208のEUC-JPにした場合の符号化。区をk、点をtとした場合、以下の式から1~2バイトで符号化する。半角カタカナがあるJIS X 0201を利用する場合は、C1制御文字のSS2 (Single Shift 2)を利用するため、最初の1バイト目は0x8Eとなる。
$$e_1 = \begin{cases} \mbox{c} & \mbox{if ASCII} \\
\mbox{0x8E} & \mbox{if JIS X 0201} \\
k+\mbox{0xA0} & \mbox{if JIS X 0208} \\
\end{cases}$$
$$e_2 = \begin{cases} \mbox{c} & \mbox{if JIS X 0201} \\
t+\mbox{0xA0} & \mbox{if JIS X 0208} \\
\end{cases}$$
式から分かる通り、0xA0を足しているだけである。区や点は、94通りしかないため、マッピング後は、0xA1~0xFEまでの値になる。
面の概念が追加されたJIS X 0213を符号化する場合は、EUC-JIS-2004での符号化となる。面をm、区をk、点をtとした場合、以下の式から1~3バイトで符号化する。m=2の場合は、C1制御文字のSS3 (Single Shift 3)を利用するため、最初の1バイト目は0x8Fとなる。
$$e_1 = \begin{cases} \mbox{c} & \mbox{if ASCII} \\
\mbox{0x8E} & \mbox{if JIS X 0201} \\
k+\mbox{0xA0} & \mbox{if JIS X 0213 } m = 1 \\
\mbox{0x8F} & \mbox{if JIS X 0213 } m = 2 \\
\end{cases}$$
$$e_2 = \begin{cases} \mbox{c} & \mbox{if JIS X 0201} \\
t+\mbox{0xA0} & \mbox{if JIS X 0213 } m = 1 \\
k+\mbox{0xA0} & \mbox{if JIS X 0213 } m = 2 \\
\end{cases}$$
$$e_3 = \begin{cases} t+\mbox{0xA0} & \mbox{if JIS X 0213 } m = 2 \\
\end{cases}$$
Unicode
一般的には符号化方式ではない。しかしWindowsのメモ帳で、文字コードをUnicodeにすると、Unicodeの文字集合で、文字符号化は「UTF-16 LE BOM付き」で保存される。従って、Windowsの世界では、UnicodeはUTF-16 LEを指す場合があるため、これもまた使用者に用語の確認が必要である。Unicodeについては、後述の予定。
まとめ
解説
JIS X 0201では、ASCIIコードと半角カタカナ。そしてJIS X 0208では、常用漢字を含んだ第一水準と、異体字を含んだ第二水準、記号が定められた。
初期のShift_JISでは、JIS X 0201とJIS X 0208を含められると規定された。IBMと、NECは、JIS X 0208に対して足りない文字を独自に拡張した。Windowsでは、Shift_JISにこれらの独自拡張文字を、追加した文字コード、Windows-31Jを定めて利用するようになった。
JIS X 0213:2004では、人名用漢字許容字体や地名で使用される漢字などの第三水準、それ以外でよく利用される漢字の第四水準が制定され、これを含めた符号化Shift_JIS-2004を作成した。Shift_JIS-2004は、本来のShift_JISとは互換性があるが、独自拡張を入れたWindows-31Jとは互換性がない符号化となった。
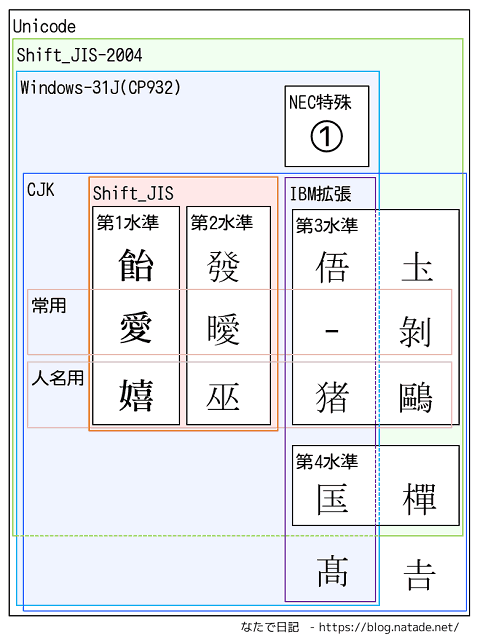
第三水準と第四水準の中には、IBM拡張文字の文字集合が含まれている。例として、IBM拡張文字の「嵂」は、第四水準の文字として決められた。逆にIBM拡張文字にあるのに、第三水準と第四水準にさえ含まれていない文字、例えば「髙」がある。
このように、IBM拡張文字が対応しているWindows-31Jは、第三水準と第四水準の一部対応という形になるし、逆に第一、第二、第三、第四にも含まれない文字、「髙」などにも対応しているということになる。
文字集合、文字コード、フォントの関係図
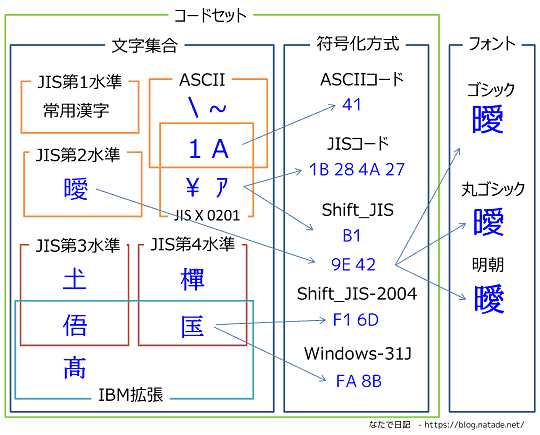
漢字と文字コードの関係図
対応している文字を調べる方法
次の漢字が表示できるかを調査すると対応している文字が大体分かります。文字は私が適当に選びました!
- 第1水準の漢字 飴愛嬉
- 第2水準の漢字 發曖巫
- 第3水準の漢字 俉𡈽圡剝猪鷗
- 第4水準の漢字 匤樿
- IBM拡張文字にある第3水準の漢字 俉猪
- IBM拡張文字にある第4水準の漢字 匤
- IBM拡張文字にない第3水準の漢字 𡈽圡剝鷗
- IBM拡張文字にない第4水準の漢字 𧲸樿
- 漢字水準外だがIBM拡張内の漢字 髙
- 漢字水準外かつIBM拡張外の漢字 𠮷
- 常用漢字 愛剥
- 新常用漢字 愛曖剝
- 人名用漢字 嬉巫猪鷗
- Shift_JISの非漢字 ◆
- JIS X 0201 アイウエオ
- NEC特殊文字 ⑳
- NEC特殊文字外のJIS X 0213非漢字 ㉑
- Unicodeでサロゲートペアが必要な第3水準の漢字 𡈽
- Unicodeでサロゲートペアが必要な第4水準の漢字 𧲸
- Unicodeで結合文字列処理が必要なJIS X 0213非漢字 カ゚
文字コード解析ツール
文字コード解析ツールを作りました
リアルタイム文字コード解析ツール
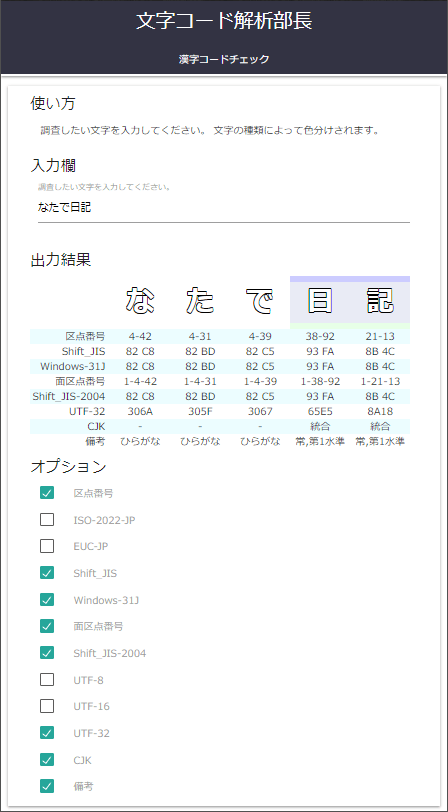
詳細は「日本語の文字コード解析ツールの紹介」
参考
- IBM拡張文字 ‐ 通信用語の基礎知識
- NEC特殊文字 ‐ 通信用語の基礎知識
- NEC選定IBM拡張文字‐ 通信用語の基礎知識
- Windows-31J ‐ 通信用語の基礎知識
- Microsoftコードページ932 – Wikipedia
- JIS漢字水準(ジス カンジスイジュン)とは – コトバンク
- JIS漢字コード – Wikipedia
- 文字コード – Wikipedia
- Shift_JIS – ウィキペディア
- 外字 – Wikipedia
- JIS X 0201 – ウィキペディア
- JIS X 0208 – ウィキペディア
- JIS X 0212 – ウィキペディア
- JIS X 0213 – ウィキペディア
- JIS X 0213漢字一覧 – Wikipedia
- JIS X 0213非漢字一覧 – Wikipedia
- Shift_JIS と Windows-31J (MS932) の違いを整理してみよう
- フォント – Wikipedia
- ITO Takayuki – 文字コードの話
- 文字コード表 JISコード(ISO-2022-JP)
コメント
とてもわかりやすいです!